

A Interação Humano-Robô (IHR) é um tópico de pesquisa que tem recebido atenção especial devido ao aumento das aplicações robóticas que auxiliam às atividades humanas [34]. Na robótica vestível para fins de reabilitação, os desafos que devem ser tratados giram em torno das seguintes questões. Em primeiro lugar, a dificuldade de proporcionar uma interação homem-robô adequada e segura, levando em consideração principalmente o comportamento incerto e variável no tempo da dinâmica do ser humano. Em segundo lugar, o projeto de controle do dispositivo robótico deve ser adaptativo e personalizado para cada usuário que veste o robô. Finalmente, a precisão que o robô deve ter para transmitir adequadamente o torque ao usuário, preservando os requisitos de estabilidade e desempenho da interação humano-robô. Diante deste cenário, é parte do esforço contínuo de nosso laboratório projetar estratégias de controle eficazes para a reabilitação assistida por robôs, principalmente nas extremidades inferiores. O objetivo é encontrar a melhor estratégia de controle que leve em conta as necessidades e características do paciente e resulte em uma recuperação mais rápida e eficaz.
O controle de impedância modela a relação dinâmica entre as grandezas de força/torque e posição/velocidade. O objetivo fundamental do controle de impedância é moldar o comportamento do sistema para corresponder ao de um modelo dinâmico desejado pré-definido [35]. Geralmente, o feedback de força/torque necessário para o funcionamento adequado do controle de impedância é feito por meio da inclusão de um elemento elástico entre o sistema de transmissão e a carga. Na robótica de reabilitação, normalmente é utilizado o Atuador Elástico em Serie (AES). Ele permite reduzir os efeitos de forças não desejadas produzidas por choques. No entanto, alguns problemas surgem, por exemplo, o armazenamento de energia passiva, folgas mecânicas, ondulações indesejadas nos sinais de força/torque, entre outras. A inclusão de um AES implica uma configuração de controle de impedância baseada em dois laços, Fig.16. Note-se que a dinâmica humana é desconhecida, incerta e variável no tempo com respeito à tarefa a ser realizada. Além disso, está diretamente ligada ao laço de controle interno. Portanto, o projeto de controlador de força/torque representa um desafio maior quando comparado ao laço externo de controle de posição/velocidade. Neste sentido, as técnicas tradicionais de controle de força/torque são insuficientes para garantir altos índices de desempenho e estabilidade robusta durantes tarefas de interação.
Em nossos trabalhos de pesquisa, defendemos a relevância da dinâmica humana no projeto de controles de interação. Nossos primeiros resultados relatados em [36] mostram que abordagens estândares de controle de força/torque comprometem o desempenho da interação humano-robô, uma vez que não atendem as características instrisecas de variabilidade da dinâmica humana. Portanto, o laço externo de posição/velocidade resulta em controladores de impedância estáveis, mas com baixo desempenho. Portanto, foi necessário a utilização de abordagens de controle de interação que incorporam a identificação dos eventos chaves que ocorrem durante a interação humano-robô. Assim, foi proposta utilização dos sistemas lineares de salto Markoviano para modelar e abordar problemas de interação humano-robô. Mudando a forma de enxergar o problema, desde uma perspectiva determinística para uma estocástica. Desta forma, foram obtidos resultados na área de regulação [37, 38, 39], estimativa e filtragem [40], e a combinação das duas técnicas em suas versões robustas [41, 42]. Além disso, foram definimos modos de operação, os quais são relacionados ao comportamento do sistema durante as tarefas de interação. As transições entre esses modos foram modeladas através das cadeias Markovianas com base em medidas cinemáticas de robôs, sinais de Eletromiografa (EMG) de músculos humanos e fases da caminhada humana.
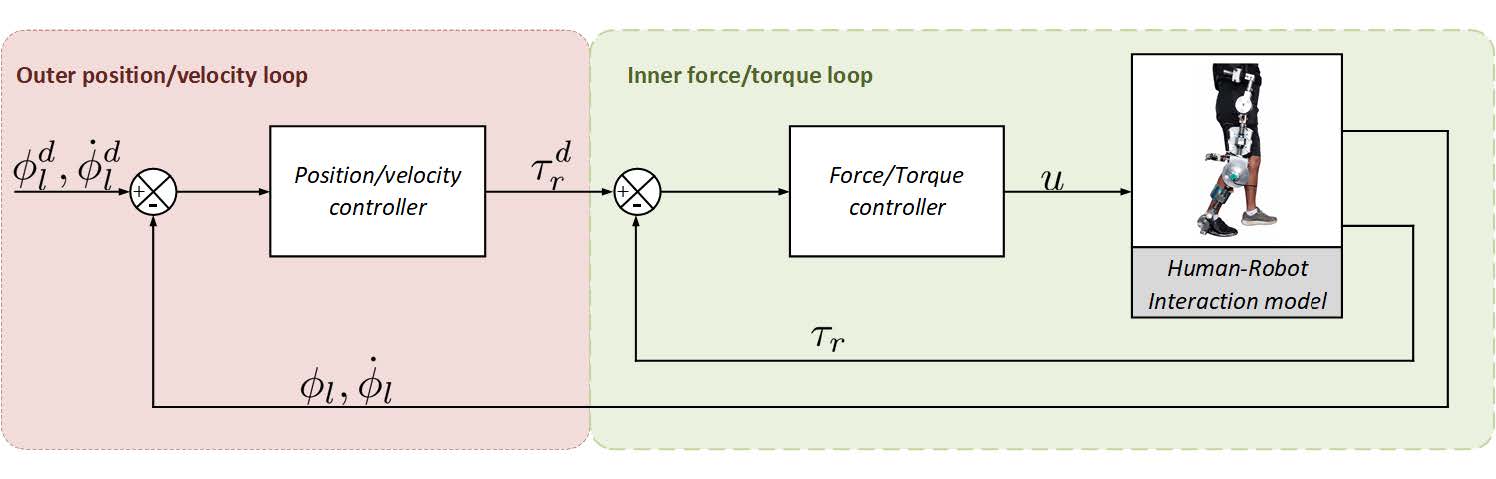
Figura 16: Controle de impedância estândar para o AES – Nesta configuração, as principais variáveis são: posição angular da carga ϕl velocidade angular ϕ˙ l, e torque do robô τr. Sinais de referencia são: posição angular desejada ϕd velocidade angular l desejada ϕ˙ ld , torque do robô desejado τd , e sinal de controle u.
Motivado pelos desafios da interação humano-robô durante o caminhar humano. Nosso trabalho de pesquisa apresentado em [41], teve como objetivo, além de lidar com os problemas de estabilidade e desempenho observados na interação humano-robô durante o caminhar, identificar as características especificas dos pacientes em sua caminhada e agir de acordo com a estratégia de controle proposta. O que resultou em uma solução personalizada para o paciente. Inicialmente, foi modelada a dinâmica da interação humano-robô como um sistema multi-modal dependente da transição de eventos. Esses eventos são associados às fases do caminhar humano. Desta forma, cada estado do sistema correlaciona-se a uma fase do caminhar, e por sua vez a sequência de fases é regida por uma lei de probabilidade que modela as transições de saltar entre estados, sendo que o estado 1 está associado ao evento de Resposta de Carregamento (LR), o estado 2 ao evento de Postura Média (MSt), o estado 3 ao evento de Postura Terminal (TSt), o estado 4 ao evento de Balanço Inicial (ISw), e fnalmente o estado 5 ao evento de Balanço Terminal (TSw), completando o ciclo da marcha humana, veja Figura 17.
Além disso, considerando um modelo de segunda ordem da atuação humana, foram estimados os valores da impedância humana durante cada fase de marcha, como mostrado na Figura 17. Consequentemente, foram sintetizados ganhos apropriados para cada fase utilizando a técnica do regulador linear quadrático de saltos Markovianos para sistemas de tempo discreto. Essa abordagem de controle é uma nova proposta de controle de torque/impedância para propósitos de reabilitação.
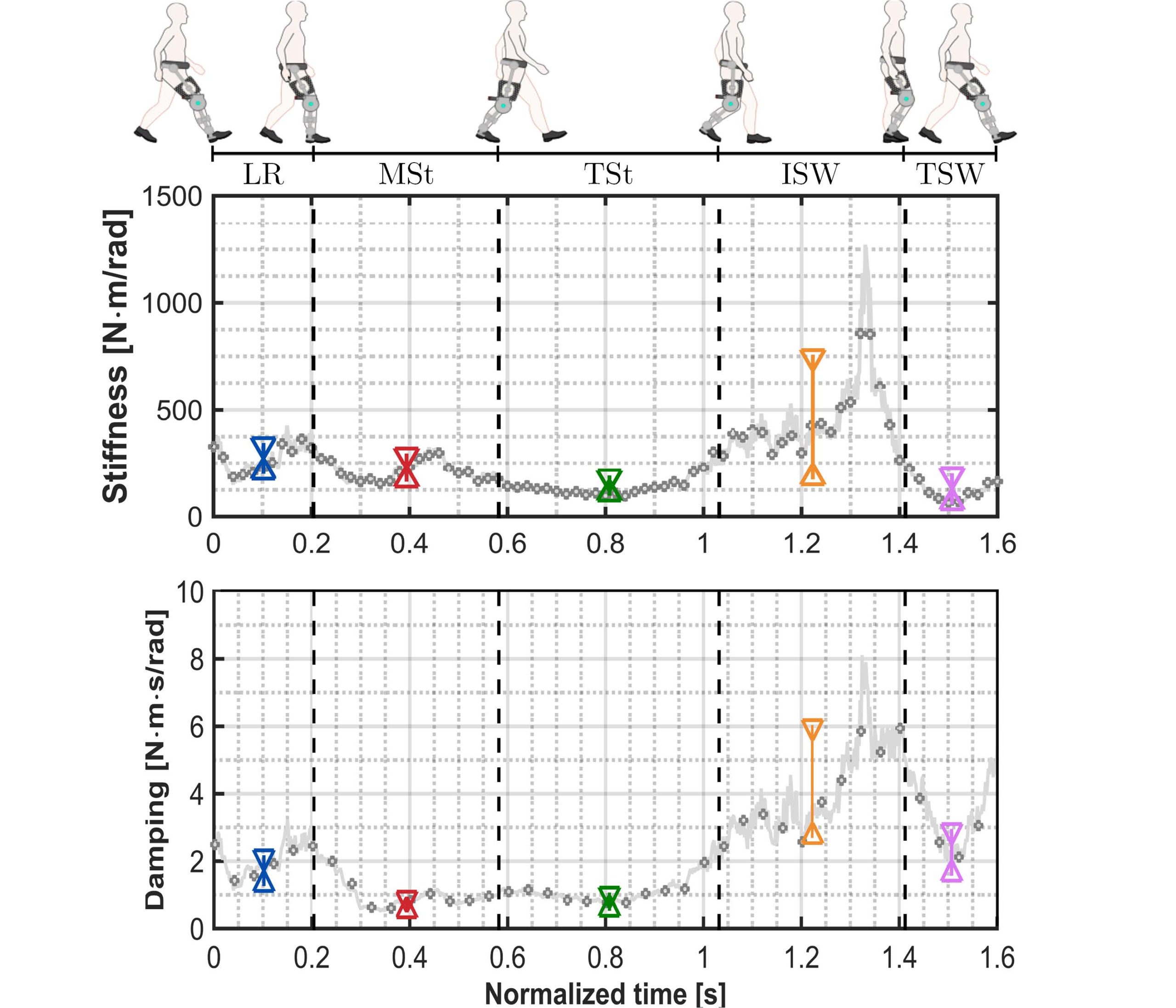
Figura 17: Rigidez e amortecimento estimados do joelho humano durante o ciclo da marcha. Cada fase da marcha é representada por uma cor diferente (LR: azul, MSt: vermelho, TSt: verde, ISW: laranja, and TSW: magenta). Ilustração adaptada de [41].
No projeto de controladores de interação em dispositivos robóticos para assistência, a segurança da interação é um dos principais objetivos tanto no nível de software quanto de hardware. Nosso interesse é garantir a segurança da interação desde o sistema de controle, uma vez que a alta magnitude de um sinal de controle pode resultar em esforço adicional do sistema de atuação causando um comportamento inseguro para o usuário durante uma tarefa especifica. Essa questão se torna ainda mais desafiadora quando o ambiente a ser controlado é altamente incerto e variável no tempo, por exemplo, quando a dinâmica humana faz parte do laço fechado de torque. O intercambio contínuo de energia entre articulações humanas e juntas robóticas pode causar instabilidade do sistema, dado que a estratégia de controle utilizada não leva em consideração mudanças bruscas de comportamento. Portanto, uma estratégia de controle adequada a ser utilizada neste tipo de aplicações deve proporcionar um comportamento autocomplacente com o usuário. Em nossas pesquisas, demonstramos em experimentos simulados e reais que nossas abordagens Markovianas garantem estabilidade, alto desempenho diante de perturbações dinâmicas e distúrbios externos. No entanto, vale a pena mencionar que abordagens do tipo Markovianas têm sido pouco exploradas no contexto da interação humano-robô, principalmente no cenário de reabilitação robótica.
Robôs manipuladores são cadeias cinemáticas compostas de elos e juntas que alcançam grande versatilidade de aplicações. Usualmente utilizados no ambiente industrial, são responsáveis por tarefas repetitivas que exigem rapidez e precisão, podendo ser programados para diversos tipos de atividades de acordo com o efetuador final utilizado, tais como pintura, montagem de placas eletrônicas, solda, dentre outras. Estes robôs também podem ser utilizados em ambientes domésticos como assistentes pessoais ou mesmo de modo a auxiliar na reabilitação de pessoas com movimentos limitados. Além disso, robôs manipuladores estão cada vez mais presentes no ambiente hospitalar para realização de cirurgias.
O foco da pesquisa no laboratório tem sido em ambientes não-estruturados e sujeitos a diversos tipos de incertezas visuais e diferentes objetos presentes em cena. Ou seja, a principal linha de pesquisa se afasta do ambiente industrial controlado e se aproxima de aplicações em cenários mais diversificados, como o doméstico e o hospitalar. Para tal, temos empregado técnicas de inteligência artifcial para dotar o robô manipulador de maior destreza e melhor percepção visual.
O robô disponível no laboratório é um modelo KINOVA GEN3, ilustrado na Fig. 18. Ele possui sete graus de liberdade, é equipado com câmera e sensor de profundidade embarcados, bem como um par de garras paralelas modelo Robotiq 2F-85. O robô possui inúmeros recursos, como controlador com fio, interface de monitoramento web, controle de admitância cartesiano e de espaço nulo, prevenção de configurações de singularidade e colisões, entre muitos outros.
O framework de software e plataforma de desenvolvimento Ki-nova KORTEX permite configurar e controlar programaticamente o robô de acordo com as particularidades da aplicação considerada. A API é usada na linguagem Python para enviar comandos de postura cartesiana, velocidade do efetuador final e abertura da garra, além de obter as leituras dos sensores e ter acesso ao stream da câmera.
A garra paralela Robotiq 2F-85 possui dois dedos articulados compostos por duas falanges e possibilita pesquisas em preensão. Ela pode prender o objeto considerando até cinco pontos de contato e é capaz de adaptar à sua forma, uma vez que os dedos são sub-atuados.

Figura 18: Kinova Gen3 com a garra Robotiq 2F-85 (Kinova Robotics)

Figura 19: Acima: Predição do retângulo de preensão para diferentes objetos captados pela câmera do robô. Nota-se que as predições são consistentes com a forma dos objetos, de modo que, ao robô fazer as transformações dos pontos da imagem para o mundo 3D, e posicionar suas garras nesses pontos, seu fechamento resultará em uma preensão estável. Abaixo: Demonstração do módulo reativo do sistema, em que a bola azul representa a imagem desejada e a bola verde representa sua posição atual. A câmera se move para visualizar a bola da maneira desejada.
Preensão de objetos é uma área de pesquisa canônica em manipulação robótica. No entanto, por ser considerado um problema aberto, conforme pode ser observado na falta de destreza com que os robôs manipulam objetos complexos, sua relevância e importância se estendem até os dias atuais.
Um bom subconjunto de hipóteses para encontrar a configuração de preensão ideal compreende o tipo de tarefa que o robô irá executar, as características do objeto alvo, que tipo de conhecimento prévio sobre o objeto está disponível, que tipo de garra é usada e, fnalmente, síntese de preensão.
A síntese de preensão, também denominada “detecção de pontos de preensão”, é o cerne do problema de preensão robótica, pois se refere à tarefa de encontrar pontos no objeto que configurem escolhas de preensão apropriadas. Estes são os pontos nos quais a garra deve realizar o contato com o objeto, garantindo que a ação de forças externas não o leve à instabilidade e satisfaça um conjunto de critérios relevantes para a tarefa de preensão.
Com o objetivo de explorar o uso de algoritmos de aprendizado profundo, especificamente Redes Neurais Convolucionais (CNN), para abordar o problema da preensão robótica, o trabalho [43] aborda a fase de percepção visual envolvida na tarefa. Para atingir este objetivo, o conjunto de dados “Cornell Grasp” foi usado para treinar uma CNN capaz de prever o local mais adequado para agarrar o objeto. A rede prediz um retângulo de preensão que simboliza a posição, orientação e abertura das garras paralelas do robô imediatamente antes de as garras serem fechadas. O sistema proposto funciona em tempo real devido ao pequeno número de parâmetros da rede. Isso é possível por meio da estratégia de aumento de dados utilizada. A efciência da detecção está de acordo com o estado da arte e a velocidade de predição é uma das maiores da literatura.
Para comprovar a execução em tempo real do sistema desenvolvido anteriormente, implementamos a rede no robô manipulador e realizamos diversos testes com objetos disponíveis no laboratório. Esses testes também possibilitaram avaliar a capacidade de generalização da rede, uma vez que os objetos considerados não foram instâncias de treinamento, estão sujeitos à diferentes condições de iluminação e são vistos por uma câmera diferente da utilizada na coleta de dados do dataset.
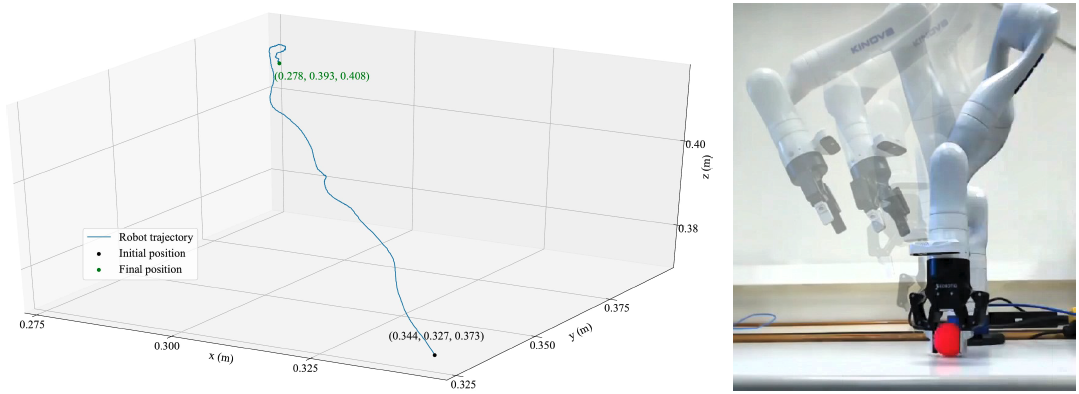
Figura 20: Esquerda: trajetória realizada pelo efetuador do robô de uma posição inicial até uma posição desejada por meio de controle servo-visual realizado pela rede desenvolvida. Mediante apenas informação visual da câmera do robô e uma imagem desejada obtida a priori, o robô atinge a postura esperada com erros de apenas 1.3mm em x, 2.3mm em y, 4mm em z, 0.56◦ em α, 0.29◦ em β e 0.57◦ em γ. Além disso, a trajetória retilínea obtida é algo altamente desejavel durante o controle servo-visual. Direita: demonstração do movimento do robô de uma posição inicial até o fechamento das garras durante uma tentativa de preensão de uma bolinha utilizando o framework fnal desenvolvido.
Além disso, outra rede foi projetada para controlar a câmera do robô de modo a manter o objeto de interesse no seu campo de visão. Dessa forma, é possível lidar com objetos móveis na cena, bem como suprimir eventuais distúrbios durante a execução, já que essa rede funciona como um módulo reativo do sistema de preensão. Assim, este trabalho, disponível em [44], apresenta um novo sistema de manipulação robótica autônoma, com capacidade de generalização para diferentes objetos e com alta velocidade de processamento, que permite sua aplicação em sistemas robóticos reais. Parte dos resultados são ilustrados na Fig. 19.
Controle servo-visual refere-se ao uso de dados de visão computacional para controlar o movimento de um robô. Os dados podem ser obtidos por uma câmera montada diretamente em um robô manipulador (eye-in-hand), caso em que o movimento do robô induz o movimento da câmera, ou pode ser fxado na área de trabalho (eye-to-hand), para que possa observar o movimento do robô em uma configuração estacionária.
O módulo reativo do sistema de manipulação robótica mencionado anteriormente se trata de uma rede neural convolucional capaz de realizar controle servo-visual. Esta rede prediz os valores proporcionais lineares e angulares da velocidade que a câmera deve ter para garantir que a imagem capturada pelo robô seja a imagem desejada (setpoint).
O conjunto de imagens para treinamento da rede foi obtido praticamente sem intervenção humana pelo próprio GEN3. Cada instância contém duas imagens do ambiente de trabalho obtidas a partir de duas posturas diferentes da câmera e os labels são os valores proporcionais das velocidades. A rede desenvolvida é extremamente leve e é executada em tempo real.
Ao fim, o controlador desenvolvido, publicado em [44], é capaz de atingir uma precisão milimétrica na posição final considerando um objeto alvo visto pela primeira vez. Até onde sabemos, não encontramos na literatura outros trabalhos que alcancem tamanha precisão com um controlador aprendido do zero. A Fig. 20 apresenta um dos resultados alcançados, do ponto de vista Cartesiano.
Embora a busca por parâmetros ótimos seja uma preocupação central para o estágio de projeto de sistemas de controle, esse ajuste geralmente não é otimizado no projeto de controladores servo-visuais. No entanto, para um controlador servo-visual clássico baseado em posição, a escolha do ganho proporcional que multiplica o erro computado pode afetar diretamente o desempenho do sistema, podendo até mesmo levar o sistema à instabilidade. Por outro lado, ajustar tal parâmetro pode ser uma tarefa demorada e trabalhosa. Assim, no trabalho [45], propomos automatizar a busca dos ganhos lineares e angulares de um controlador por meio da otimização Bayesiana. Simulamos o ambiente em Matlab com o robô GEN3 em um cenário de aprendizado por reforço, no qual a função de custo projetada é avaliada diretamente no robô. Demonstramos que a otimização Bayesiana é capaz de encontrar os ganhos do controlador servo-visual, bem como os ganhos do controlador interno do robô, com até 13 e 14 vezes menos iterações quando comparado a um algoritmo ator-crítico e um algoritmo genético, respectivamente. Além disso, mostramos que o controlador obtido tem melhor desempenho considerando diferentes parâmetros de desempenho de controle e em avaliações qualitativas em relação aos espaços Cartesiano e de imagem.
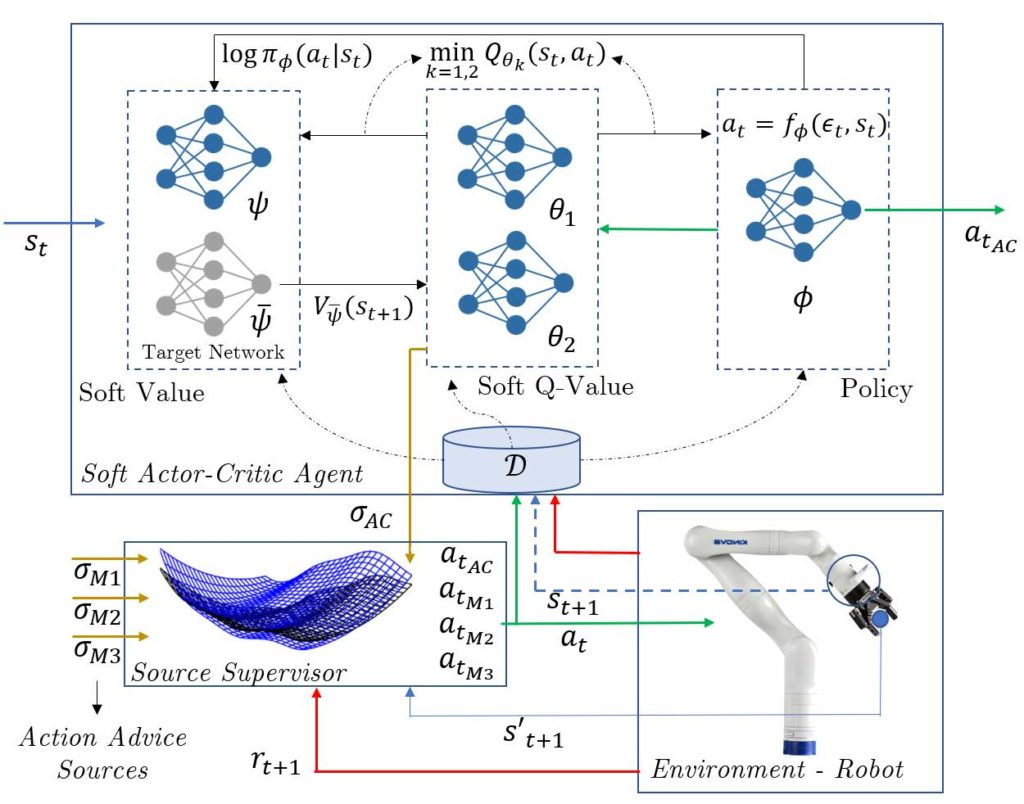
Figura 21: Framework Bayesiano de aprendizagem porr efor¸co: um otimizador Bayesiano avalia e decide qual controlador deve executar uma a¸c˜ao no robˆo; essa a¸c˜ao otimizada acelera a aprenizagem do agente Soft Actor-Critic.
Aprendizagem por reforço sofre notadamente com o problema de ineficiência amostral, especialmente se o objetivo envolver capacidade de generalização. Neste trabalho (em andamento) buscamos obter um controlador servo-visual por meio de aprendizagem por reforço, cuja eficiência na interação com o ambiente seja aprimorada por um módulo de otimização Bayesiana. Esta estrutura tem alicerce na premissa de aprendizagem por reforço baseada em modelo, no qual um modelo conhecido ou aprendido está disponível e pode ser explorado para guiar ações no ambiente e/ou atualizar o Q-valor ou a política. Na estrutura desenvolvida, os modelos disponíveis são outros controladores servo-visuais projetados separadamente, ou seja, pretende-se treinar um agente capaz de solicitar um “action advice” para um dos modelos disponíveis quando sua incerteza sobre a ação a ser tomada for muito alta. Para tal, um módulo de otimização Bayesiana de múltiplas fontes será projetado para gerenciar o treinamento, ou seja, para dizer se um “action advice” é necessário e qual será sua fonte. A Fig. 21 sumariza o sistema. As variáveis que guiarão a escolha do otimizador são a incerteza associada a cada modelo e o custo de sua execução. Os estados observados são as imagens atual e desejada e a ação predita é a velocidade (linear e angular) da câmera do robô.
A identificação dinâmica de um robô manipulador é um problema importante em robótica e geralmente é resolvido empregando a técnica dos mínimos quadrados, considerando os chamados parâmetros base do robô. Tais parâmetros, no entanto, diferem daqueles aos quais realmente queremos ter acesso, como o centro de massa e os momentos de inércia em relação a esse centro. Além disso, a solução obtida por esta técnica pode levar a parâmetros inadequados do ponto de vista físico, o que requer uma etapa posterior de análise de viabilidade física. No trabalho [46], buscamos superar essas desvantagens identificando os parâmetros do GEN3 usando apenas metaheurísticas baseadas em população. Fazemos um estudo entre diferentes técnicas e as comparamos com a otimização Bayesiana, outra abordagem caixa-preta. Também propomos um novo algoritmo chamado Otimização Diferencial Probabilística (PDO) e mostramos que este algoritmo é mais eficiente que os outros considerados e pode encontrar uma solução fisicamente viável devido à sua capacidade de exploração probabilística. Também estudamos a necessidade de mais de uma trajetória de excitação para superar o ruído de medição e o overftting e, finalmente, obter parâmetros precisos do GEN3 com a garra 2F-85. Parte da metodologia e dos resultados são ilustrados na Fig. 22.
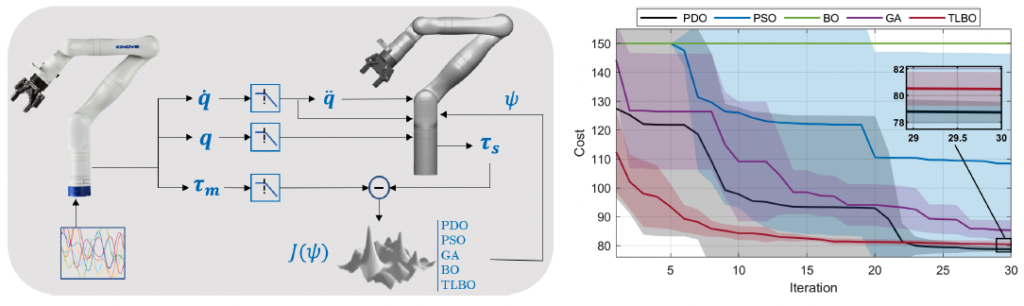
Figura 22: Esquerda: Visão geral do método proposto. As juntas do modelo real são excitadas usando série de Fourier. Posição (q), velocidade (q˙ ) e torque (τm) são medidos e filtrados. q, q˙ e q¨ (aceleração derivada de q˙ ) são enviados para o modelo simulado. O torque calculado τs é comparado com τm por meio da função custo J(ψ), que é minimizada para encontrar os parâmetros dinâmicos ψ. Direita: Evolução do valor do custo J(ψ) para diferentes algoritmos de otimização. A técnica desenvolvida (PDO) gera o menor custo e possui a menor variância (sombreado), levando a valores mais precisos dos parâmetros dinâmicos.
[34] B. Hobbs and P. Artemiadis, “A review of robot-assisted lower-limb stroke therapy: Unexplored paths and future directions in gait rehabilitation,” Frontiers in Neurorobotics, vol. 14, pp. 1–16, 2020.
[35] N. Hogan, “Impedance control: An approach to manipulation: Parts I-III,” Journal of Dynamic Systems, Measurement, and Control, vol. 107, no. 1, pp. 17–24, 1985.
[36] J. C. Pérez-Ibarra, A. Alarcón, J. C. Jaimes, F. M. Escalante, M. H. Terra, and A. A. G. Siqueira, “Design and analysis of H∞ force control of a series elastic actuator for impedance control of an ankle rehabilitation robotic platform,” in 2017 American Control Conference, (Seatle, USA), pp. 2423–2428, IEEE, May 2017.
[37] A. L. Jutinico, J. C. Jaimes, F. M. Escalante, J. C. Pérez-Ibarra, M. H. Terra, and A. A. G. Siqueira, “Impedance control for robotic rehabilitation: A robust Markovian approach,” Frontiers in Neurorobotics, vol. 11, no. 43, pp. 1–16, 2017.
[38] A. L. Jutinico, J. C. Jaimes, F. M. Escalante, J. C. Pérez-Ibarra, M. H. Terra, and A. A. G. Siqueira, “Recursive robust regulator for discrete-time Markovian jump linear systems: Control of series elastic actuators,” in 20th IFAC World Congress, vol. 50, (Tolouse, France), pp. 1340 – 1345, IFAC-PapersOnLine, July 2017.
[39] A. L. Jutinico, F. M. Escalante, J. C. Jaimes, M. H. Terra, and A. A. G. Siqueira, “Markovian robust compliance control based on electromyographic signals,” in 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), (Enschede, Netherlands), pp. 1218–1223, IEEE, August 2018.
[40] F. M. Escalante, A. L. Jutinico, J. C. Jaimes, A. A. G. Siqueira, and M. H. Terra, “Robust Kalman flter and robust regulator for discrete-time Markovian jump linear systems: Control of series elastic actuators,” in 2018 IEEE Conference on Control Technology and Applications (CCTA), (Copenhagen, Denmark), pp. 976–981, August 2018.
[41] F. M. Escalante, J. C. Pérez-Ibarra, J. C. Jaimes, A. A. Siqueira, and M. H. Terra, “Robust markovian impedance control applied to a modular knee-exoskeleton,” IFAC-PapersOnLine, vol. 53, pp. 10141–10147, July 2020. 21st IFAC World Congress.
[42] F. M. Escalante, A. L. Jutinico, J. C. Jaimes, M. H. Terra, and A. A. G. Siqueira, “Markovian robust fltering and control applied to rehabilitation robotics,” IEEE/ASME Transactions on Mechatronics, vol. 26, pp. 491–502, February 2021.
[43] E. G. Ribeiro and V. Grassi, “Fast convolutional neural network for real-time robotic grasp detection,” in 2019 19th International Conference on Advanced Robotics (ICAR), pp. 49–54, IEEE, 2019.
[44] E. G. Ribeiro, R. de Queiroz Mendes, and V. Grassi Jr, “Real-time deep learning approach to visual servo control and grasp detection for autonomous robotic manipulation,” Robotics and Autonomous Systems, vol. 139, p. 103757, 2021.
[45] E. G. Ribeiro, R. Q. Mendes, M. H. Terra, and V. Grassi, “Bayesian optimization for efcient tuning of visual servo and computed torque controllers in a reinforcement learning scenario,” in 2021 20th International Conference on Advanced Robotics (ICAR), pp. 282–289, IEEE, 2021.
[46] E. G. Ribeiro, R. Q. Mendes, M. H. Terra, and V. Grassi, “Dynamic parameter identifcation of a 7-dof lightweight robot manipulator using probabilistic diferential optimization,” in 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), p. To be published, IEEE, 2022.

A Escola de Engenharia de São Carlos (EESC) é uma das unidades de ensino, pesquisa e extensão da Universidade de São Paulo (USP), instituição pública e de padrão mundial.
INSTITUCIONAL
Área 1 – Avenida Trabalhador são-carlense, 400
Pq Arnold Schimidt – CEP 13566-590 – São Carlos – SP
Área 2 – Avenida João Dagnone, 1100
Jd. Santa Angelina – CEP 13563-120 – São Carlos – SP
CRHEA – Rodovia Domingos Innocentini, Km 13
Represa do Lobo (Broa) – Itirapina – SP
A Escola de Engenharia de São Carlos (EESC) é uma das unidades de ensino, pesquisa e extensão da Universidade de São Paulo (USP), instituição pública e de padrão mundial.
INSTITUCIONAL
Área 1 – Avenida Trabalhador são-carlense, 400
Pq Arnold Schimidt – CEP 13566-590 – São Carlos – SP
Área 2 – Avenida João Dagnone, 1100
Jd. Santa Angelina – CEP 13563-120 – São Carlos – SP
CRHEA – Rodovia Domingos Innocentini, Km 13
Represa do Lobo (Broa) – Itirapina – SP
A Escola de Engenharia de São Carlos (EESC) é uma das unidades de ensino, pesquisa e extensão da Universidade de São Paulo (USP), instituição pública e de padrão mundial.
INSTITUCIONAL
Área 1 – Avenida Trabalhador são-carlense, 400
Pq Arnold Schimidt – CEP 13566-590 – São Carlos – SP
Área 2 – Avenida João Dagnone, 1100
Jd. Santa Angelina – CEP 13563-120 – São Carlos – SP
CRHEA – Rodovia Domingos Innocentini, Km 13
Represa do Lobo (Broa) – Itirapina – SP